Amazon S3
Realizando o upload de arquivo na nuvem usando o Amazon S3
Antes disso precisamos criar uma conta e registrar o usuário. Vou pular a etapa de criação da conta pois é algo bem simples.
Realizada a criação da conta na AWS, vamos criar um usuário para utilizarmos em nossa aplicação. Acesse o painel do IAM: https://console.aws.amazon.com/iam/
E depois criaremos o usuário. Pode usar um desses caminhos destacados:
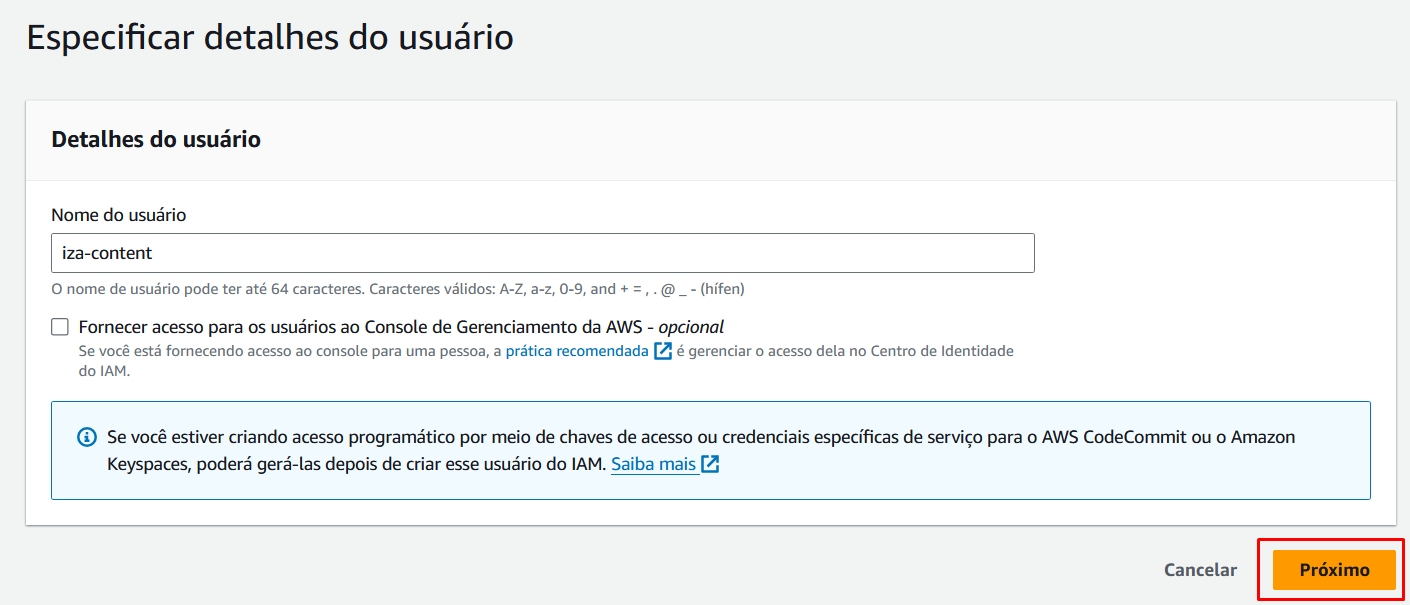
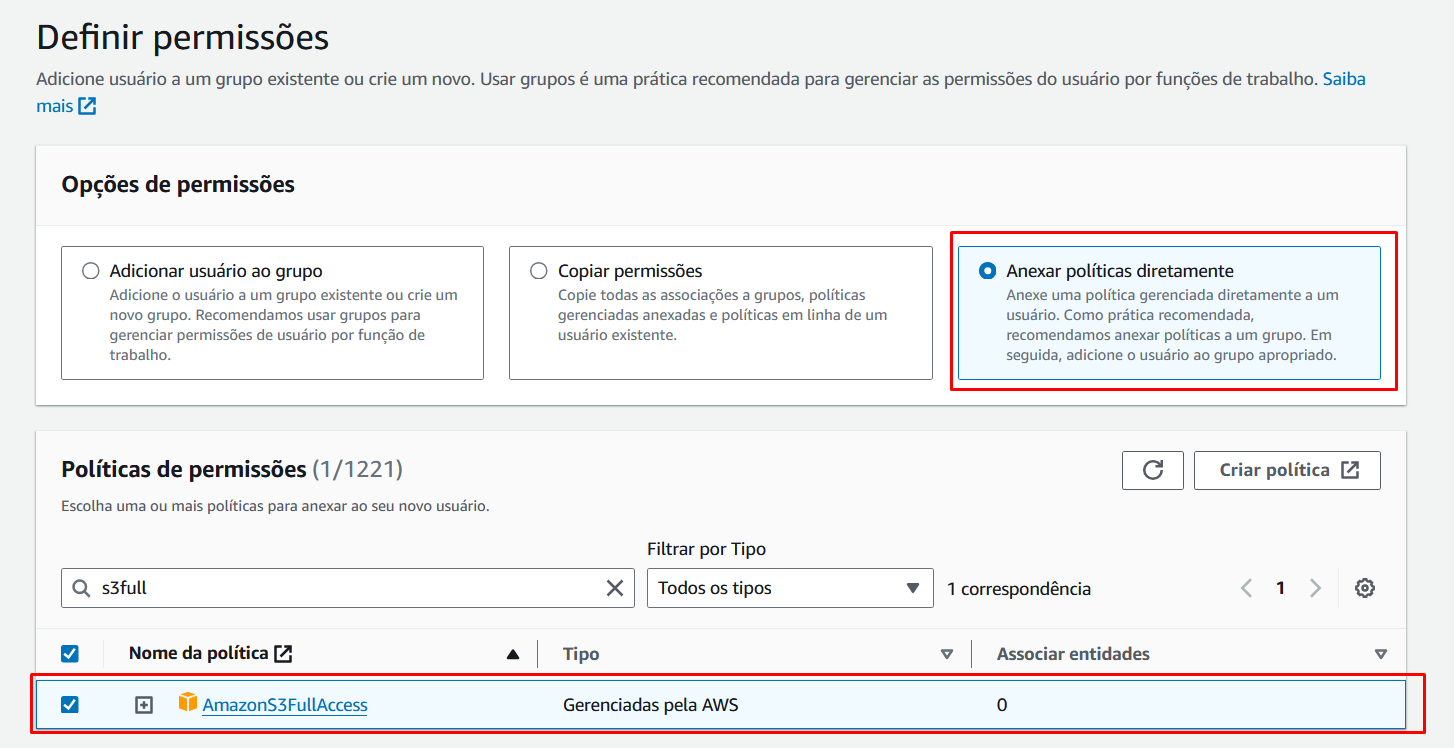
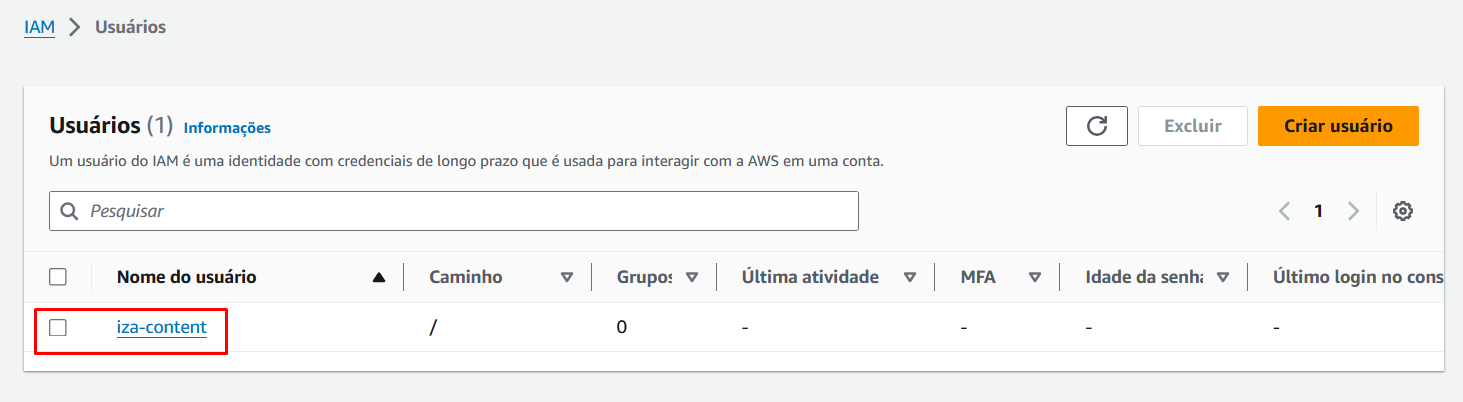
Com o usuário criado, vamos selecioná-lo para criar a chave de acesso:
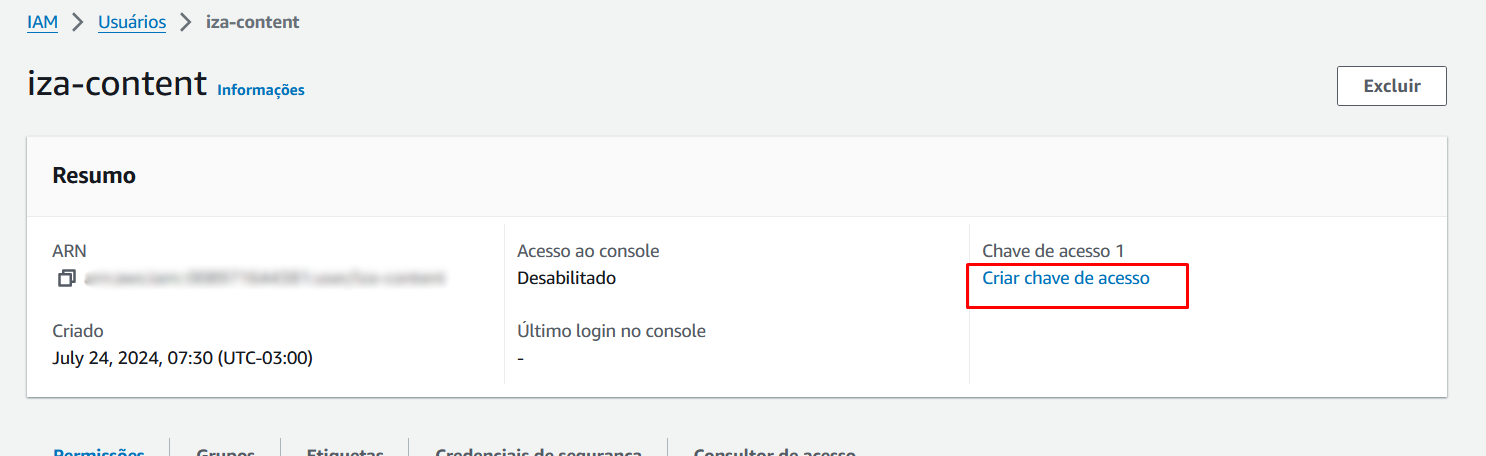
Na criação da chave, selecione a opção que mais te atende nas Práticas recomendadas e alternativas para chaves de acesso, no caso escolhi o Código local, depois defina uma descrição para essa chave. E depois avance.
Pronto sua chave de acesso e chave acesso secreta estão criadas!
Agora vamos criar nosso bucket, que na verdade é um contêiner para armazenar arquivos na Amazon S3, nisso, cada arquivo estará armazenado em um bucket.
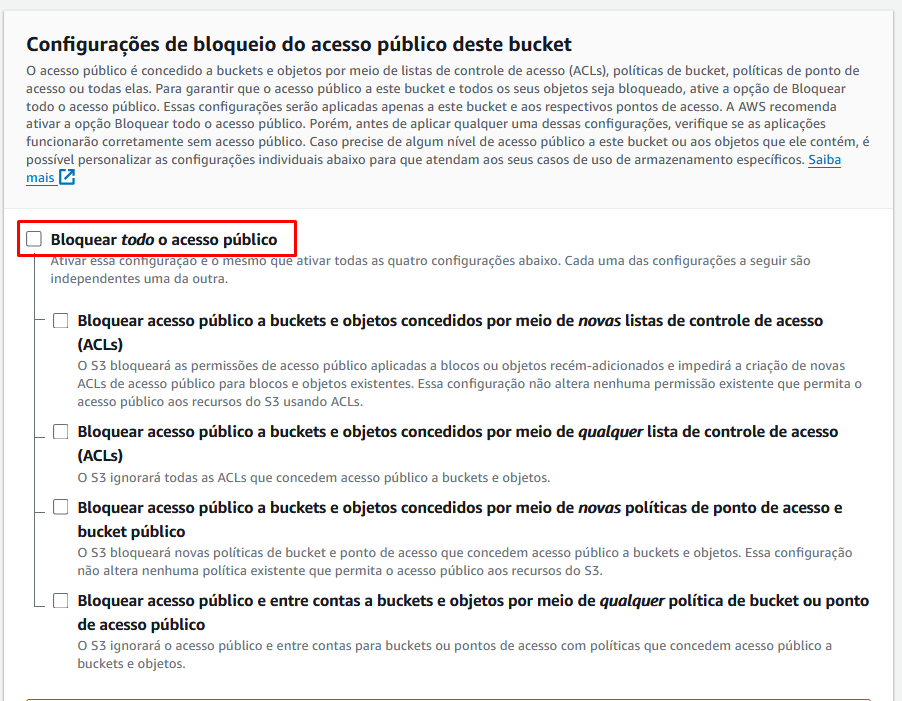
As demais configurações podemos deixar padrão.
Agora vamos avançar!
Não podemos esquecer de adicionar a dependência da AWS:
<dependency>
<groupId>software.amazon.awssdk</groupId>
<artifactId>s3</artifactId>
<version>2.17.89</version>
</dependency>
Dessa vez vamos precisar de um local para armazenar as nossas credenciais da AWS. São chamadas as variáveis de ambiente, e vamos deixar no nosso arquivo application.properties.
aws.accessKeyId=seu id da chave de acesso
aws.secretKey=chave secreta
aws.region=região (Ex: us-east-1)
aws.bucket=nome do seu bucket
As informações de id da chave de acesso e a chave secreta foram geradas quando depois de criar o nosso usuário, fomos em Criar chave de acesso. A região e por último o nome do bucket.
Vamos adicionar um novo pacote de configuração para configurar o cliente Amazon S3 na nossa aplicação Spring. A anotação @Configuration indica que a classe definições de beans que serão gerenciados pelo contêiner do Spring. Já a anotação @Value são usadas para injetar os valores que configuramos na application.properties, sem a necessidade de deixar estático no código.
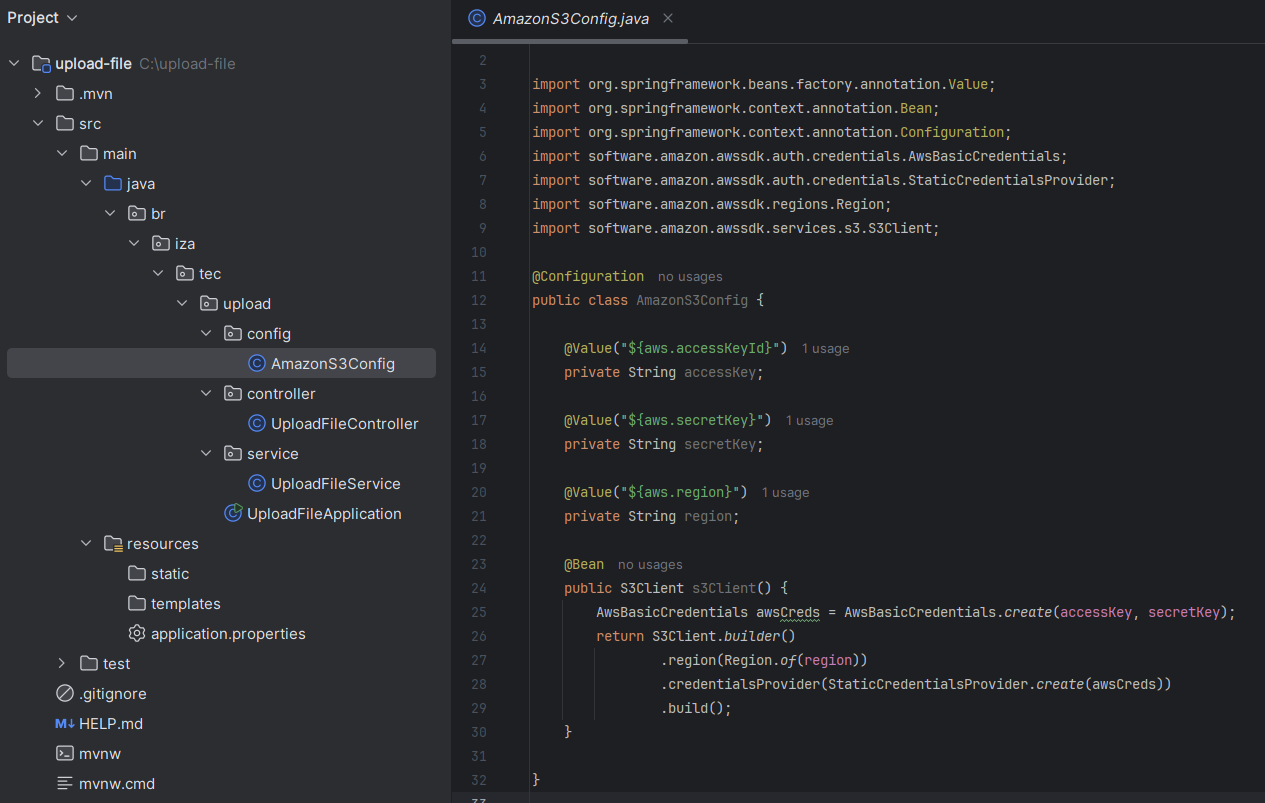
No método s3Client cria um objeto de credenciais básicas da AWS e são necessárias para autenticação e acesso da Amazon S3:
- O S3Client inicia a construção de um cliente;
- Em seguida vem a informação da região que o bucket está localizado;
- A
.credentialsProvider(StaticCredentialsProvider.create(awsCreds))fornece as credenciais criadas anteriormente ao cliente S3; - Por fim, o
build()finaliza a construção do cliente S3 e o retorna como um bean gerenciado pelo Spring.
Mas cuidado ao subir para o repositório remoto, certifique-se de não deixar a mostra as suas credenciais. Aproveite e dá uma pesquisada outras alternativas para guardar as variáveis e chaves secretas em seu código 🤓
Assim como fizemos nas classes de Service e Controller na ação de salvar localmente, vamos ter o método de salvar na nuvem nessas também:
@Service
public class UploadFileService {
@Value("${aws.bucket}")
private String bucket;
public String salvarNaNuvem(MultipartFile file) throws Exception {
String fileName = file.getOriginalFilename();
PutObjectRequest request = PutObjectRequest.builder()
.bucket("projetouploadfile")
.key(fileName)
.build();
PutObjectResponse response = s3Client.putObject(request, RequestBody.fromInputStream(file.getInputStream(), file.getSize()));
return response.eTag();
}
O método salvarNaNuvem da classe de Service, possibilita o upload de um arquivo diretamente para o bucket. Vamos analisá-lo:
- Adicionamos um novo atributo para que possamos pegar o nome do bucket e adicionar em nossos métodos;
- O
MultipartFileaparece novamente, pois representa o arquivo a ser enviado para o S3; - O
fileNamevai pegar o nome original do arquivo e será usado como a chave (key) no bucket do S3; - O
PutObjectRequesté um objeto que vai ser responsável para encapsular os detalhes da solicitação de upload. Aqui passamos o nome do bucket e a key; - Já no
s3Client.putObjectfaz o upload para o S3, onde é realizada a as informações do bucket (request) eRequestBodypermite que os dados do arquivo sejam enviados diretamente sem a necessidade de salvar temporariamente; - Por fim,
response.eTag()retorna a Etag do objeto enviado. A Etag é um identificador para uma versão específica de um recurso no HTTP, que permite verificar a integridade do arquivo enviado.
E no método salvarNaNuvem na classe Controller é bem parecido com o salvar localmente, a diferença está na variável etag que captura a ETag retornada e, se o upload for bem-sucedido, retorna uma resposta HTTP 200 (OK) com a mensagem "Upload realizado com sucesso!".
Acessando o arquivo na nuvem
Antes de acessarmos o arquivo na nuvem, vamos só adicionar dois métodos, na Service e Controller:
public byte[] verArquivoNaNuvem(String fileName) throws Exception {
GetObjectRequest request = GetObjectRequest.builder()
.bucket("projetouploadfile")
.key(fileName)
.build();
ResponseBytes<GetObjectResponse> responseBytes = s3Client.getObjectAsBytes(request);
return responseBytes.asByteArray();
}
O método verArquivoNaNuvem na Service utiliza getObjectAsBytes para obter o arquivo da Amazon S3 como um array de bytes. O endpoint /ver-arquivo-na-nuvem na Controller chama este método e retorna o conteúdo do arquivo como uma resposta HTTP.
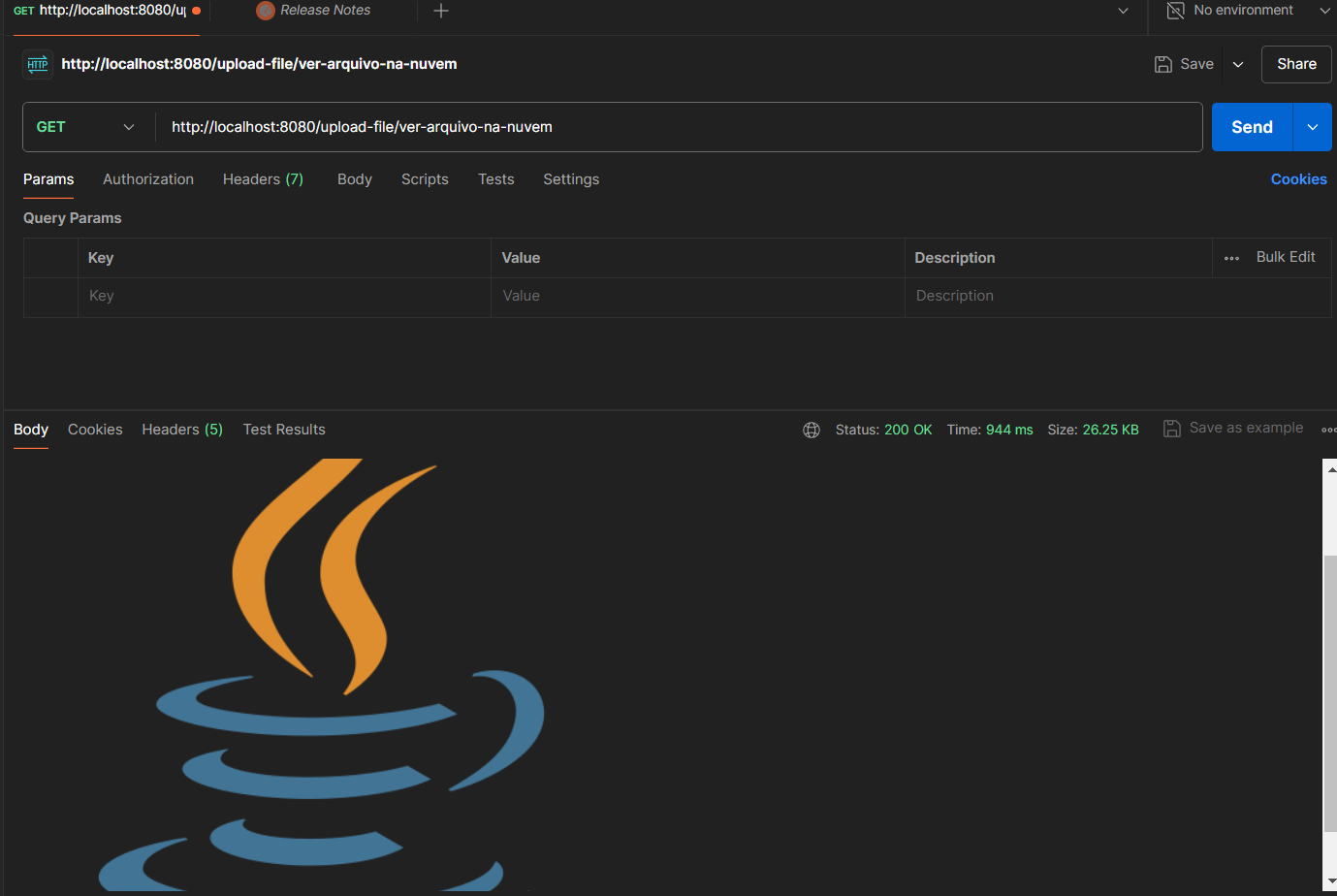
Uilizando o Swagger:
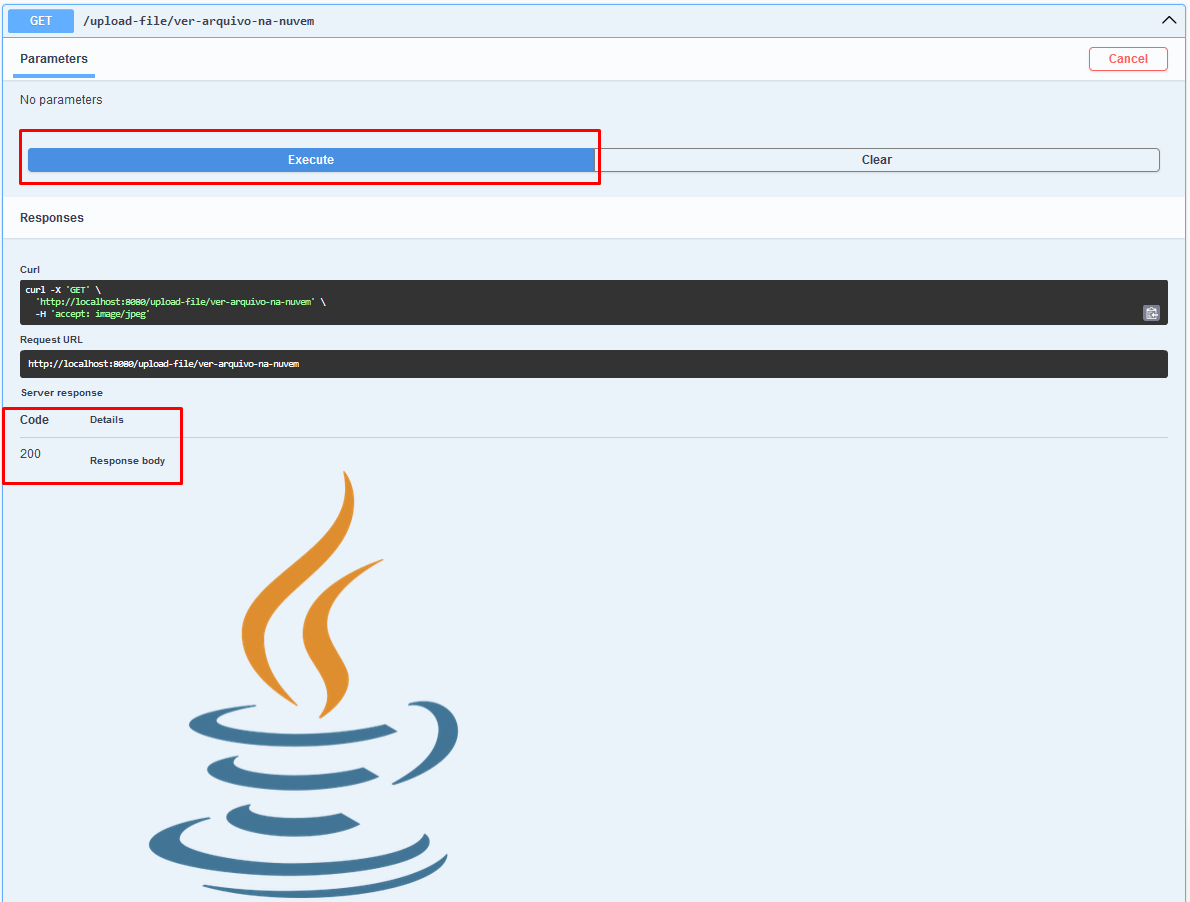
E agora utilizando o Postman: