Spring Data JPA
Se você está integrando sua aplicação a uma database baseado em ORM, então você deve conhecer sobre Spring Data JPA.
O Spring Data JPA adiciona uma camada sobre o JPA. Isso significa que ele usa todos os recursos definidos pela especificação JPA, especialmente o mapeamento de entidades e os recursos de persistência baseado em interfaces e anotações. Por isso, o Spring Data JPA adiciona seus próprios recursos, como uma implementação sem código do padrão de repositório e a criação de consultas de banco de dados a partir de nomes de métodos.

A partir de agora,nossa interação com o banco de dados será através de herança de interfaces e declaração de métodos com anotações.
Existem algumas interfaces e anotações que são super relevantes de explorar como:
Interfaces
- CrudRepository
- JPARepository
- PagingAndSortingRepository
Anotações
- @Query
- @Param
Projeto Maven
Criando um projeto pelo Spring Initialzr:
Acesse o site https://start.spring.io/ e coloque as informações com sugeridas abaixo:
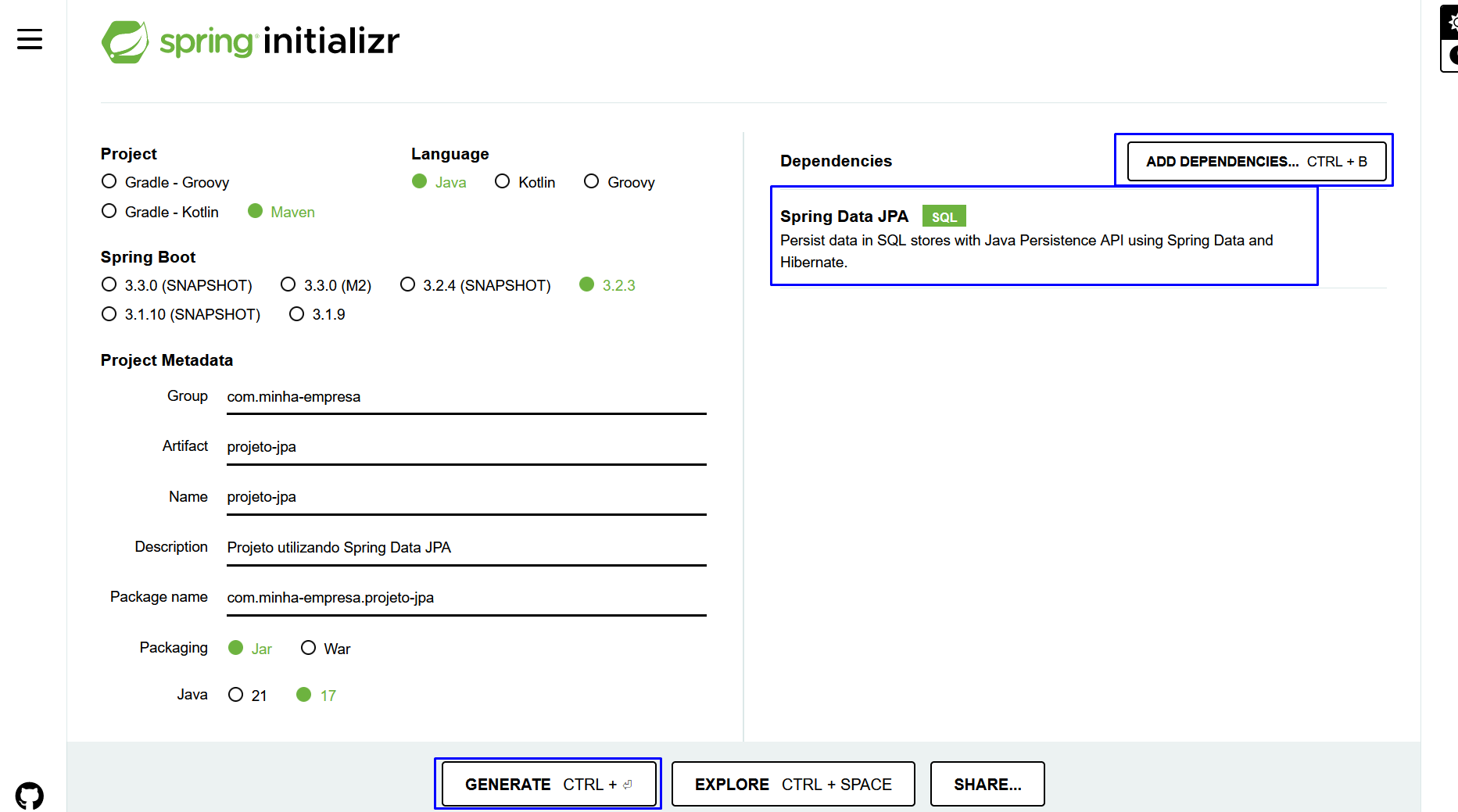
Importe na IDE de sua preferência com um projeto Maven e aguarde realizar o download de todas as dependências necessárias.
Mapeamento
Conheça as principais anotações do JPA.
Vamos imaginar que fomos designados a implementar um cadastro de usuário conforme diagrama abaixo:
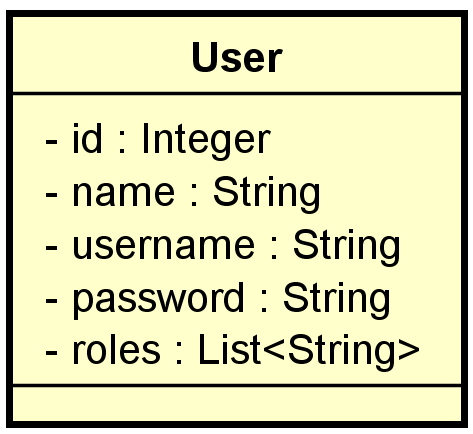
Com os recursos do Spring Data JPA poderemos incluir, alterar, listar e excluir nossos usuários em uma base de dados.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
Mapeando a classe User.java
import javax.persistence.*;
import java.util.List;
@Entity
@Table(name = "tab_user")
public class User {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id_user")
private Integer id;
@Column(length = 50, nullable = false)
private String name;
@Column(length = 20, nullable = false)
private String username;
@Column(length = 100, nullable = false)
private String password;
@Transient
private List<String> roles;
public User(){
}
public User(String username){
this.username = username;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public List<String> getRoles() {
return roles;
}
public void setRoles(List<String> roles) {
this.roles = roles;
}
public Integer getId() {
return id;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", username='" + username + '\'' +
", password='" + password + '\'' +
", roles=" + roles +
'}';
}
}
Conhecendo as anotações
- @Entity: Torna a classe um entidade conectada a uma tabela no banco de dados
- @Table: Necessário quando o nome da entidade difere do nome da tabela
- @Id: Determina que o atributo representa a chave primária no banco de dados
- @GeneratedValue: Determina a geração da chave primária
- @Column: Necessário quando precisamos informar propriedade de definição DDL na entidade
- @Transient: Quando o atributo não possui relação com nenhum campo no banco de dados
Primeira Persistência
Hora de persistir nossas entidades em um banco de dados.
Primeiro de tudo precisamos confirmar se nosso projeto contém o Start do spring-data-jpa.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
Criando o repositório
import org.springframework.data.jpa.repository.JpaRepository;
public interface UserRepository extends JpaRepository<User, Integer> {
}
Com o Spring Data JPA utilizamos interfaces para estender outras interfaces disponíveis pelo framework, precisando somente informar a classe e o tipo do campo @Id da entidade.
Primeiro CRUD
Crie a classe StartApplication implementando CommandLineRunner.
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.stereotype.Component;
@Component
public class StartApplication implements CommandLineRunner {
@Autowired
private UserRepository repository;
@Override
public void run(String... args) throws Exception {
User user = new User();
user.setName("GLEYSON");
user.setUsername("glysns");
user.setPassword("spring-data-jpa");
user.setRoles(null);
repository.save(user);
for(User u: repository.findAll()){
System.out.println(u);
}
}
}
Vamos esclarecer as principais linhas de código:
- Na linha 8 estamos injetando o nosso UserRepository através na anotação @Autowired
- Na linha 16 inserimos o usuário no banco de dados
- Da linha 18 até 20 listamos os usuários existentes no banco de dados
spring.jpa.show-sql=true no arquivos applications.propertiesExecute sua aplicação a partir da sua classe que contém a anotação @SpringBootApplication.
Hibernate: insert into tab_user (id_user, name, password, username) values (null, ?, ?, ?)
Hibernate: select user0_.id_user as id_user1_0_, user0_.name as name2_0_, user0_.password as password3_0_, user0_.username as username4_0_ from tab_user user0_
User{name='GLEYSON', username='glysns', password='spring-data-jpa', roles=null}
Qualquer Bando de Dados
Conecte o seu projeto Spring Boot em qualquer banco de dados relacional.
O projeto Spring Data JPA é capaz de se conectar a qualquer banco de dados relacional.

Em um projeto Spring Boot toda a parte de configuração fica centralizada no arquivo application.properties inclusive configurações de banco. Vamos demonstrar uma configuração para acessar o banco de dados PostgreSQL mas serve para todos os bancos de dados relacionais.
# Opcional
spring.jpa.show-sql=true
spring.jpa.hibernate.ddl-auto=update
# Obrigatório de acordo com o seu banco de dados
spring.jpa.database-platform=org.hibernate.dialect.PostgreSQLDialect
spring.datasource.driverClassName=org.postgresql.Driver
spring.datasource.url=jdbc:postgresql://localhost:5432/seu_db
spring.datasource.username=seu_user
spring.datasource.password=seu_pass
- A linha 2: Quando deseja exibir todo sql gerado no console.
- A linha 3: O JPA é capaz de criar as tabelas do sistema conforme mapeamento.
- A linha 6: Determina a plataforma de interpretação de SQL.
- A linha 7: O drive do banco de dados.
- A linha 8: A URL do banco de dados.
- A linha 9: O usuário do banco de dados.
- A linha 10: A senha do banco de dados.
Nova dependência no pom.xml
<!-- POSTGRES -->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
O Poderoso Repository
Explorando os principais recursos do JPA Repository.
Repository Pattern
Repository é um padrão de projeto similar ao DAO (Data Access Object) no sentido de que seu objetivo é abstrair o acesso a dados de forma genérica a partir do seu modelo.
Spring Data JPA
O projeto Spring Data JPA facilita a implementação do padrão Repository através de AOP (Aspect Oriented Programming - programação orientada a aspectos).
Utilizando-se apenas de uma interface, o Spring irá "gerar" dinamicamente a implementação dos métodos de acesso a dados. Estender a interface JpaRepository é opcional, mas a vantagem é que ela já vem com vários de métodos
genéricos de CRUD e você não precisa redefinir todos eles.
O repositório seria uma classe para buscar informações no banco de dados ou no local onde as informações foram persistidas. Mas no caso do JpaRepository ele provê a ligação a determinada classe do Model com possibilidade de persistir no banco de dados. https://pt.stackoverflow.com/questions/4088/utilizando-o-reposit%C3%B3rio-do-jpa
Principais métodos que já são disponibilizados pelo framework:
- save: Insere e atualiza os dados de uma entidade.
- findById: Retorna o objeto localizado pelo seu ID.
- existsById: Verifique a existência de um objeto pelo ID informado, retornando o boolean.
- findAll: Retorna uma coleção contendo todos os registros da tabela no banco de dados.
- delete: Deleta um registro da respectiva tabela mapeada do banco de dados.
- count: retorna a quantidade de registros de uma tabela mapeada no banco de dados.
Consultas Customizadas
Existem duas maneiras de realizar consultas customizadas, uma é conhecida como QueryMethod e a outra é QueryOverride.
Query Method
O Spring Data JPA se encarrega de interpretar a assinatura de um método (nome + parâmetros) para montar a JPQL correspondente.
Veja o exemplo de uma entidade que possui um endereço de e-mail e sobrenome e gostaria de filtrar por estes dois atributos.
public interface UserRepository extends Repository<User, Long> {
List<User> findByEmailAddressAndLastname(String emailAddress, String lastname);
}
Conforme a documentação oficial do Spring Data JPA, abaixo estão algumas instruções possíveis para montar JPQLs via métodos.
Query Override
Vamos imaginar que você precisará montar uma query um tanto avançada mas ficaria inviável utilizar o padrão QueryMethod? Como nossos repositórios são interfaces não temos implementação de código,
é ai que precisa definir a consulta de forma manual através da anotação @Query.
Os dois métodos realizam a mesma instrução SQL, consultando os usuários pelo seu campo name comparando com o perador LIKE do SQL.
public interface UserRepository extends JpaRepository<User, Integer> {
//Query Method - Retorna a lista de usuários contendo a parte do name
List<User> findByNameContaining(String name);
//Query Override - Retorna a lista de usuários contendo a parte do name
@Query("SELECT u FROM User u WHERE u.name LIKE %:name%")
List<User> filtrarPorNome(@Param("name") String name);
//Query Method - Retorna um usuário pelo campo username
User findByUsername(String username);
}